
Here I am going to report what appears to be strange behaviour in my greta models, at least as far as I understand things. I have found these issues in every model that I have been using personally, but I found that they also affect one of the examples from the greta website (I’ve only tried this one, so don’t know about the others). This is the example:
n_env <- 6
n_sites <- 100
## n_sites x n_env matrix of environmental variables
env <- matrix(rnorm(n_sites * n_env), nrow = n_sites)
## n_sites observations of species presence or absence
occupancy <- rbinom(n_sites, 1, 0.5)
alpha <- normal(0, 10)
beta <- normal(0, 10, dim = n_env)
## logit-linear model
linear_predictor <- alpha + env %*% beta
p <- ilogit(linear_predictor)
## distribution (likelihood) over observed values
distribution(occupancy) <- bernoulli§
mod <- model(alpha, beta)
test_mod <- mcmc(mod, warmup = 1000, n_samples = 10, thin = 1)
##
## running 4 chains simultaneously on up to 12 cores##
warmup 0/1000 | eta: ?s
warmup == 50/1000 | eta: 14s
warmup ==== 100/1000 | eta: 10s
warmup ====== 150/1000 | eta: 8s
warmup ======== 200/1000 | eta: 7s
warmup ========== 250/1000 | eta: 6s
warmup =========== 300/1000 | eta: 6s
warmup ============= 350/1000 | eta: 5s
warmup =============== 400/1000 | eta: 5s
warmup ================= 450/1000 | eta: 4s
warmup =================== 500/1000 | eta: 4s
warmup ===================== 550/1000 | eta: 3s
warmup ======================= 600/1000 | eta: 3s
warmup ========================= 650/1000 | eta: 2s
warmup =========================== 700/1000 | eta: 2s
warmup ============================ 750/1000 | eta: 2s
warmup ============================== 800/1000 | eta: 1s
warmup ================================ 850/1000 | eta: 1s
warmup ================================== 900/1000 | eta: 1s
warmup ==================================== 950/1000 | eta: 0s
warmup ====================================== 1000/1000 | eta: 0s
##
sampling 0/10 | eta: ?sI have discovered a number of issues, which all started when I noticed that the progress bar on my models always had a highly inaccurate time estimate when they started, that suggested the sampling was slowing down over time. Indeed, this was what was happening. First of all, I will give everyone my session info for context (I really hope this is just a versioning issue!):
tensorflow::tf_version()## [1] '1.12'sessionInfo()## R version 3.5.0 (2018-04-23)
## Platform: x86_64-w64-mingw32/x64 (64-bit)
## Running under: Windows 7 x64 (build 7601) Service Pack 1
##
## Matrix products: default
##
## locale:
## [1] LC_COLLATE=English_Australia.1252 LC_CTYPE=English_Australia.1252
## [3] LC_MONETARY=English_Australia.1252 LC_NUMERIC=C
## [5] LC_TIME=English_Australia.1252
##
## attached base packages:
## [1] stats graphics grDevices utils datasets methods base
##
## other attached packages:
## [1] greta_0.3.0.9001
##
## loaded via a namespace (and not attached):
## [1] Rcpp_1.0.0 whisker_0.3-2 knitr_1.20
## [4] magrittr_1.5 hms_0.4.1 progress_1.2.0
## [7] lattice_0.20-35 R6_2.3.0 rlang_0.3.1
## [10] stringr_1.3.1 globals_0.12.4 tools_3.5.0
## [13] parallel_3.5.0 grid_3.5.0 coda_0.19-2
## [16] tfruns_1.4 htmltools_0.3.6 yaml_2.1.19
## [19] digest_0.6.18 assertthat_0.2.0 crayon_1.3.4
## [22] tensorflow_1.10 Matrix_1.2-14 base64enc_0.1-3
## [25] codetools_0.2-15 evaluate_0.10 rmarkdown_1.11
## [28] stringi_1.2.4 compiler_3.5.0 prettyunits_1.0.2
## [31] jsonlite_1.5 reticulate_1.10 future_1.10.0
## [34] listenv_0.7.0 pkgconfig_2.0.1reticulate::py_config()## python: C:\Users\u1013287\AppData\Local\Continuum\miniconda3\envs\r-tensorflow\python.exe
## libpython: C:/Users/u1013287/AppData/Local/Continuum/miniconda3/envs/r-tensorflow/python36.dll
## pythonhome: C:\Users\u1013287\AppData\Local\Continuum\miniconda3\envs\r-tensorflow
## version: 3.6.7 |Anaconda, Inc.| (default, Dec 10 2018, 20:35:02) [MSC v.1915 64 bit (AMD64)]
## Architecture: 64bit
## numpy: C:\Users\u1013287\AppData\Local\Continuum\miniconda3\envs\r-tensorflow\lib\site-packages\numpy
## numpy_version: 1.15.4
## tensorflow: C:\Users\u1013287\AppData\Local\Continuum\miniconda3\envs\r-tensorflow\lib\site-packages\tensorflow\__init__.p
##
## python versions found:
## C:\Users\u1013287\AppData\Local\Continuum\miniconda3\envs\r-tensorflow\python.exe
## C:\Users\u1013287\AppData\Local\Continuum\miniconda3\python.exeFirst I will check the tensorflow graph size of the model, which we will use again later.
reticulate::py_len(attr(test_mod, "model_info")$model$dag$tf_graph$as_graph_def()$node)## [1] 1482The most simple odd thing I’ve noticed is the computational time effects of thinning. My understanding is that the MCMC chain should always sample n_samples, but then thinning just throws away a certain number of those samples. This would suggest to me that thinning should not affect the computational time of a chain (accept for the hopefully minimal overhead of deleting the samples and/or transferring the samples between tensorflow and R). However, when I use different thinning levels, the computation time is roughly linear in the number of “kept” samples and adds a fairly substantial amount of time (for large models it is massively slower to not thin):
n_kept <- c(2, 4, 5, 10, 20, 50, 100)
n_thin <- as.integer(100 / n_kept)
timing <- list()
for(i in seq_along(n_kept)){
timing[[i]] <- system.time(extra_samples(test_mod, n_samples = 100, thin = n_thin[i], verbose = FALSE))
print(i)
}
## [1] 1
## [1] 2
## [1] 3
## [1] 4
## [1] 5
## [1] 6
## [1] 7user_time <- sapply(timing, function(x) x[1])
plot(user_time ~ n_kept)
abline(lm(user_time ~ n_kept))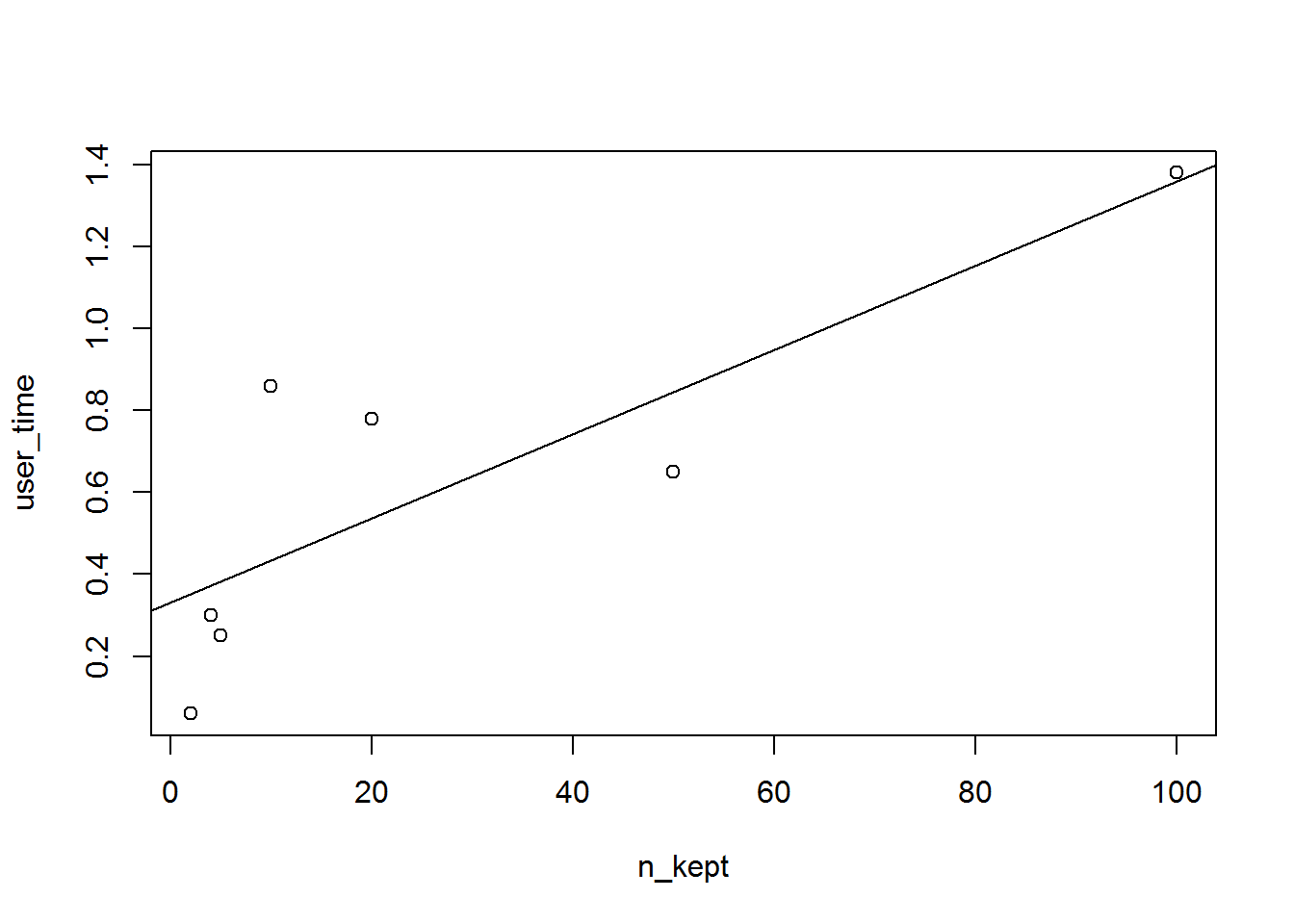
Is this a bug? It certaintly doesn’t seem right to me.
Anyway, I started by saying that I noticed originally that my models seemed to be slowing down over time. Again, my understanding of MCMC is that computation time for sampling should more or less be constant. I think this is something happening in tensorflow, because when I make entirely new models in greta they are also slowerif I haven’t reset my R session after running an “old” model. Here is an example. All I am doing is just repeatedly running mcmc on the same model. Each time it gets slower. I also output some information from the tensorflow session: the graph size, and the “sample_batch”.
timing <- list()
node_num <- list()
sampler_batch <- list()
for(i in 1:50) {
timing[[i]] <- system.time(
test_mod <- mcmc(mod, warmup = 0L, thin = 50, n_samples = 500, verbose = FALSE)
)
## save graph size
node_num[[i]] <- reticulate::py_len(attr(test_mod, "model_info")$model$dag$tf_graph$as_graph_def()$node)
## save "sample_batch" tensors
sampler_batch[[i]] <- attr(test_mod, "model_info")$samplers[[1]]$model$dag$tf_environment$sampler_batch
}
user_time <- sapply(timing, function(x) x[1])
plot(user_time, type = "l")
abline(lm(user_time~seq(1, length(timing))))
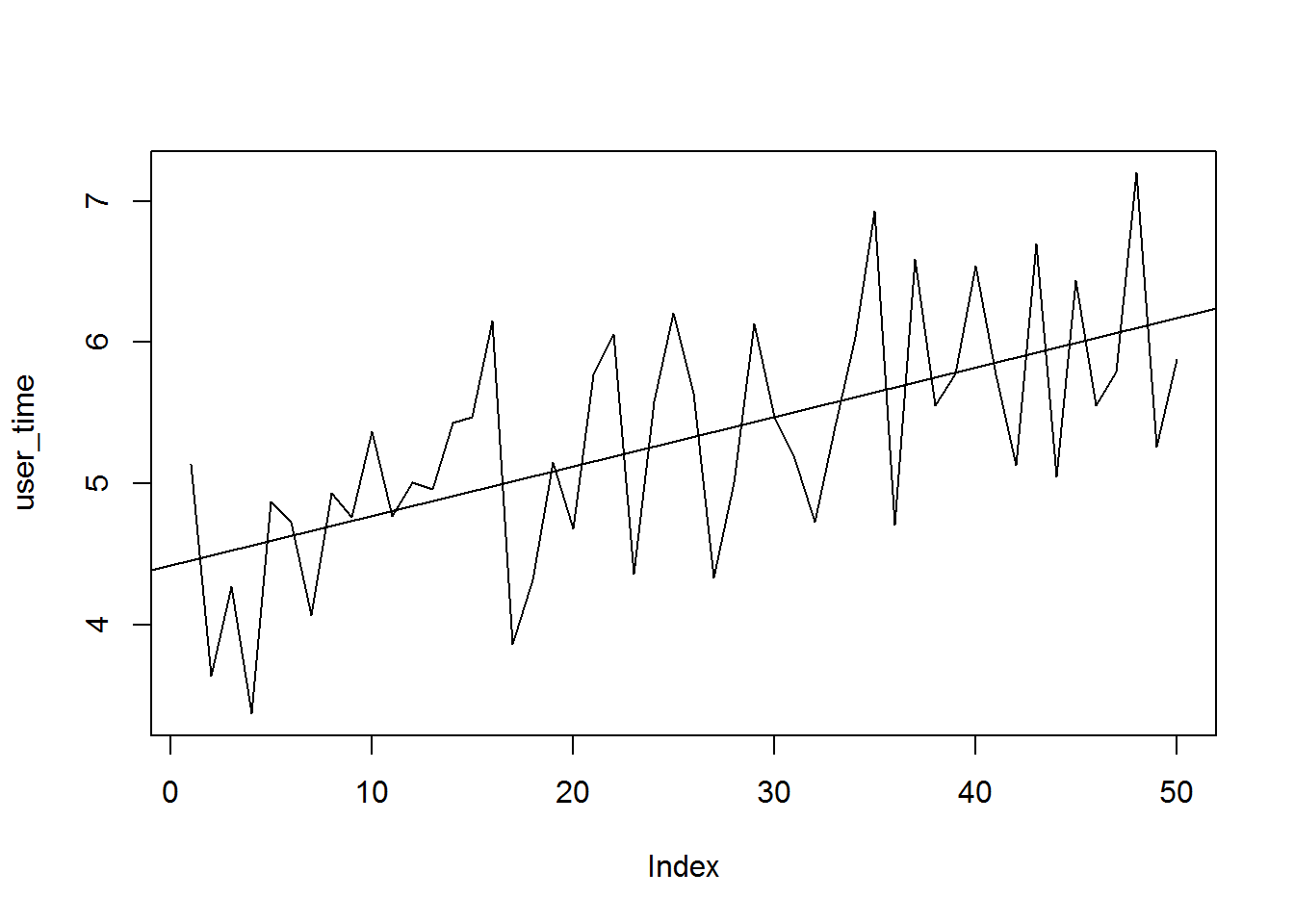
If we examine the graph sizes, they increase everytime mcmc has been run, which is weird.
unlist(node_num)## [1] 2825 4168 5511 6854 8197 9540 10883 12226 13569 14912 16255
## [12] 17598 18941 20284 21627 22970 24313 25656 26999 28342 29685 31028
## [23] 32371 33714 35057 36400 37743 39086 40429 41772 43115 44458 45801
## [34] 47144 48487 49830 51173 52516 53859 55202 56545 57888 59231 60574
## [45] 61917 63260 64603 65946 67289 68632plot(unlist(node_num))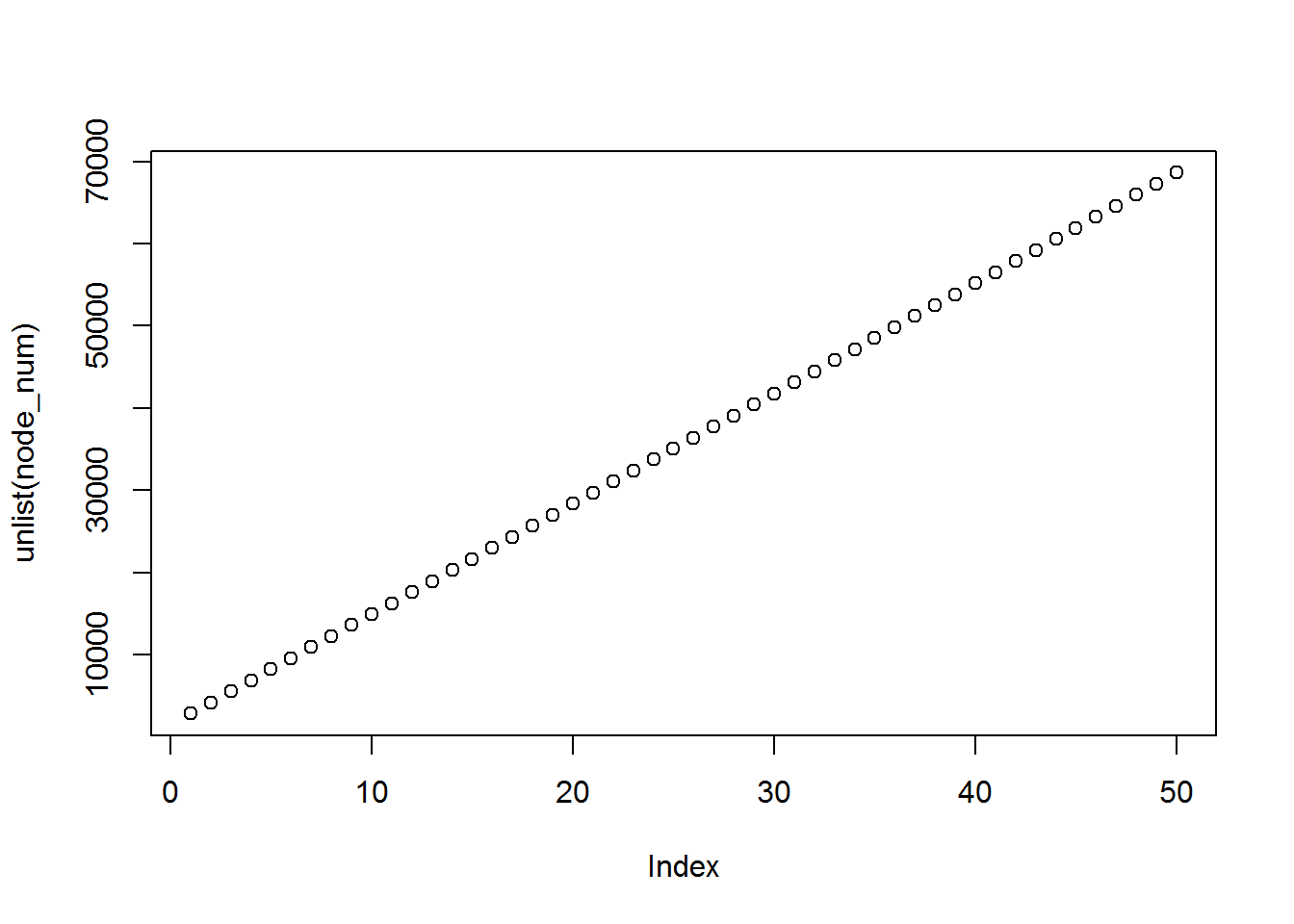
lapply(sampler_batch, function(x) x[[1]])## [[1]]
## Tensor("mcmc_sample_chain_1/scan/TensorArrayStack/TensorArrayGatherV3:0", shape=(?, ?, 7), dtype=float64)
##
## [[2]]
## Tensor("mcmc_sample_chain_2/scan/TensorArrayStack/TensorArrayGatherV3:0", shape=(?, ?, 7), dtype=float64)
##
## [[3]]
## Tensor("mcmc_sample_chain_3/scan/TensorArrayStack/TensorArrayGatherV3:0", shape=(?, ?, 7), dtype=float64)
##
## [[4]]
## Tensor("mcmc_sample_chain_4/scan/TensorArrayStack/TensorArrayGatherV3:0", shape=(?, ?, 7), dtype=float64)
##
## [[5]]
## Tensor("mcmc_sample_chain_5/scan/TensorArrayStack/TensorArrayGatherV3:0", shape=(?, ?, 7), dtype=float64)
##
## [[6]]
## Tensor("mcmc_sample_chain_6/scan/TensorArrayStack/TensorArrayGatherV3:0", shape=(?, ?, 7), dtype=float64)
##
## [[7]]
## Tensor("mcmc_sample_chain_7/scan/TensorArrayStack/TensorArrayGatherV3:0", shape=(?, ?, 7), dtype=float64)
##
## [[8]]
## Tensor("mcmc_sample_chain_8/scan/TensorArrayStack/TensorArrayGatherV3:0", shape=(?, ?, 7), dtype=float64)
##
## [[9]]
## Tensor("mcmc_sample_chain_9/scan/TensorArrayStack/TensorArrayGatherV3:0", shape=(?, ?, 7), dtype=float64)
##
## [[10]]
## Tensor("mcmc_sample_chain_10/scan/TensorArrayStack/TensorArrayGatherV3:0", shape=(?, ?, 7), dtype=float64)
##
## [[11]]
## Tensor("mcmc_sample_chain_11/scan/TensorArrayStack/TensorArrayGatherV3:0", shape=(?, ?, 7), dtype=float64)
##
## [[12]]
## Tensor("mcmc_sample_chain_12/scan/TensorArrayStack/TensorArrayGatherV3:0", shape=(?, ?, 7), dtype=float64)
##
## [[13]]
## Tensor("mcmc_sample_chain_13/scan/TensorArrayStack/TensorArrayGatherV3:0", shape=(?, ?, 7), dtype=float64)
##
## [[14]]
## Tensor("mcmc_sample_chain_14/scan/TensorArrayStack/TensorArrayGatherV3:0", shape=(?, ?, 7), dtype=float64)
##
## [[15]]
## Tensor("mcmc_sample_chain_15/scan/TensorArrayStack/TensorArrayGatherV3:0", shape=(?, ?, 7), dtype=float64)
##
## [[16]]
## Tensor("mcmc_sample_chain_16/scan/TensorArrayStack/TensorArrayGatherV3:0", shape=(?, ?, 7), dtype=float64)
##
## [[17]]
## Tensor("mcmc_sample_chain_17/scan/TensorArrayStack/TensorArrayGatherV3:0", shape=(?, ?, 7), dtype=float64)
##
## [[18]]
## Tensor("mcmc_sample_chain_18/scan/TensorArrayStack/TensorArrayGatherV3:0", shape=(?, ?, 7), dtype=float64)
##
## [[19]]
## Tensor("mcmc_sample_chain_19/scan/TensorArrayStack/TensorArrayGatherV3:0", shape=(?, ?, 7), dtype=float64)
##
## [[20]]
## Tensor("mcmc_sample_chain_20/scan/TensorArrayStack/TensorArrayGatherV3:0", shape=(?, ?, 7), dtype=float64)
##
## [[21]]
## Tensor("mcmc_sample_chain_21/scan/TensorArrayStack/TensorArrayGatherV3:0", shape=(?, ?, 7), dtype=float64)
##
## [[22]]
## Tensor("mcmc_sample_chain_22/scan/TensorArrayStack/TensorArrayGatherV3:0", shape=(?, ?, 7), dtype=float64)
##
## [[23]]
## Tensor("mcmc_sample_chain_23/scan/TensorArrayStack/TensorArrayGatherV3:0", shape=(?, ?, 7), dtype=float64)
##
## [[24]]
## Tensor("mcmc_sample_chain_24/scan/TensorArrayStack/TensorArrayGatherV3:0", shape=(?, ?, 7), dtype=float64)
##
## [[25]]
## Tensor("mcmc_sample_chain_25/scan/TensorArrayStack/TensorArrayGatherV3:0", shape=(?, ?, 7), dtype=float64)
##
## [[26]]
## Tensor("mcmc_sample_chain_26/scan/TensorArrayStack/TensorArrayGatherV3:0", shape=(?, ?, 7), dtype=float64)
##
## [[27]]
## Tensor("mcmc_sample_chain_27/scan/TensorArrayStack/TensorArrayGatherV3:0", shape=(?, ?, 7), dtype=float64)
##
## [[28]]
## Tensor("mcmc_sample_chain_28/scan/TensorArrayStack/TensorArrayGatherV3:0", shape=(?, ?, 7), dtype=float64)
##
## [[29]]
## Tensor("mcmc_sample_chain_29/scan/TensorArrayStack/TensorArrayGatherV3:0", shape=(?, ?, 7), dtype=float64)
##
## [[30]]
## Tensor("mcmc_sample_chain_30/scan/TensorArrayStack/TensorArrayGatherV3:0", shape=(?, ?, 7), dtype=float64)
##
## [[31]]
## Tensor("mcmc_sample_chain_31/scan/TensorArrayStack/TensorArrayGatherV3:0", shape=(?, ?, 7), dtype=float64)
##
## [[32]]
## Tensor("mcmc_sample_chain_32/scan/TensorArrayStack/TensorArrayGatherV3:0", shape=(?, ?, 7), dtype=float64)
##
## [[33]]
## Tensor("mcmc_sample_chain_33/scan/TensorArrayStack/TensorArrayGatherV3:0", shape=(?, ?, 7), dtype=float64)
##
## [[34]]
## Tensor("mcmc_sample_chain_34/scan/TensorArrayStack/TensorArrayGatherV3:0", shape=(?, ?, 7), dtype=float64)
##
## [[35]]
## Tensor("mcmc_sample_chain_35/scan/TensorArrayStack/TensorArrayGatherV3:0", shape=(?, ?, 7), dtype=float64)
##
## [[36]]
## Tensor("mcmc_sample_chain_36/scan/TensorArrayStack/TensorArrayGatherV3:0", shape=(?, ?, 7), dtype=float64)
##
## [[37]]
## Tensor("mcmc_sample_chain_37/scan/TensorArrayStack/TensorArrayGatherV3:0", shape=(?, ?, 7), dtype=float64)
##
## [[38]]
## Tensor("mcmc_sample_chain_38/scan/TensorArrayStack/TensorArrayGatherV3:0", shape=(?, ?, 7), dtype=float64)
##
## [[39]]
## Tensor("mcmc_sample_chain_39/scan/TensorArrayStack/TensorArrayGatherV3:0", shape=(?, ?, 7), dtype=float64)
##
## [[40]]
## Tensor("mcmc_sample_chain_40/scan/TensorArrayStack/TensorArrayGatherV3:0", shape=(?, ?, 7), dtype=float64)
##
## [[41]]
## Tensor("mcmc_sample_chain_41/scan/TensorArrayStack/TensorArrayGatherV3:0", shape=(?, ?, 7), dtype=float64)
##
## [[42]]
## Tensor("mcmc_sample_chain_42/scan/TensorArrayStack/TensorArrayGatherV3:0", shape=(?, ?, 7), dtype=float64)
##
## [[43]]
## Tensor("mcmc_sample_chain_43/scan/TensorArrayStack/TensorArrayGatherV3:0", shape=(?, ?, 7), dtype=float64)
##
## [[44]]
## Tensor("mcmc_sample_chain_44/scan/TensorArrayStack/TensorArrayGatherV3:0", shape=(?, ?, 7), dtype=float64)
##
## [[45]]
## Tensor("mcmc_sample_chain_45/scan/TensorArrayStack/TensorArrayGatherV3:0", shape=(?, ?, 7), dtype=float64)
##
## [[46]]
## Tensor("mcmc_sample_chain_46/scan/TensorArrayStack/TensorArrayGatherV3:0", shape=(?, ?, 7), dtype=float64)
##
## [[47]]
## Tensor("mcmc_sample_chain_47/scan/TensorArrayStack/TensorArrayGatherV3:0", shape=(?, ?, 7), dtype=float64)
##
## [[48]]
## Tensor("mcmc_sample_chain_48/scan/TensorArrayStack/TensorArrayGatherV3:0", shape=(?, ?, 7), dtype=float64)
##
## [[49]]
## Tensor("mcmc_sample_chain_49/scan/TensorArrayStack/TensorArrayGatherV3:0", shape=(?, ?, 7), dtype=float64)
##
## [[50]]
## Tensor("mcmc_sample_chain_50/scan/TensorArrayStack/TensorArrayGatherV3:0", shape=(?, ?, 7), dtype=float64)Also, printing the “sample_batch” tensors, we can see that the name of the tensor, “mcmc_sample_chain_i”, has been iterated by 1 with each run of mcmc. I don’t know enough about tensorflow to know what this means exactly but perhaps it could help with diagnosing the problem?
Now, I originally noted the slowdown when using extra_samples, not by repeatedly calling mcmc, so what happens when we use extra_samples instead? Well, for one thing, the graph size no longer seems to increase.
timing <- list()
node_num <- list()
sampler_batch <- list()
for(i in 1:100) {
timing[[i]] <- system.time(
test_mod <- extra_samples(test_mod, thin = 50, n_samples = 500, verbose = FALSE)
)
}
user_time <- sapply(timing, function(x) x[1])
plot(user_time, type = "l")
abline(lm(user_time~seq(1, length(timing))))
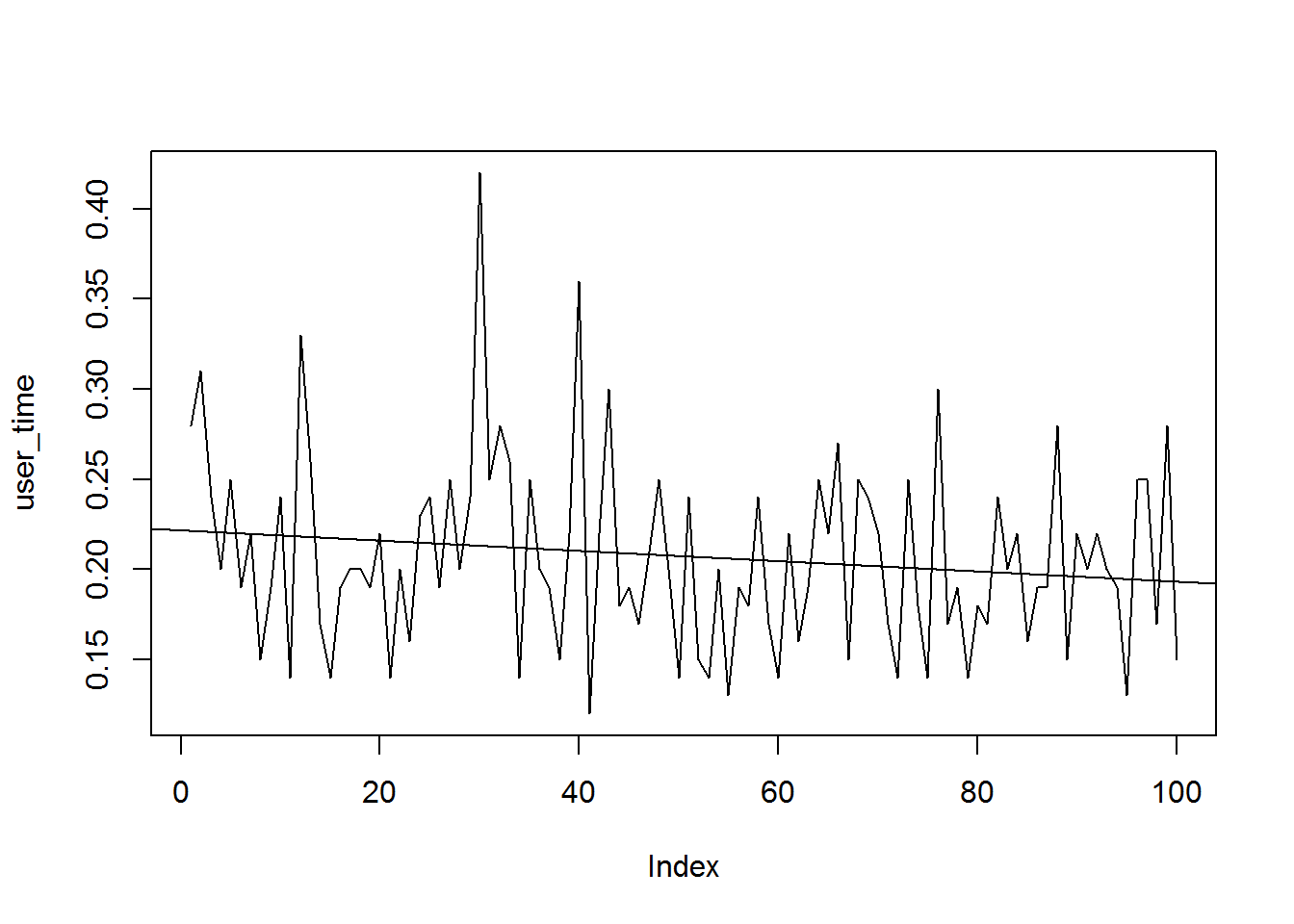
Confirm graph size has not changed with extra_samples:
reticulate::py_len(attr(test_mod, "model_info")$model$dag$tf_graph$as_graph_def()$node)## [1] 68632attr(test_mod, "model_info")$samplers[[1]]$model$dag$tf_environment$sampler_batch[[1]]## Tensor("mcmc_sample_chain_50/scan/TensorArrayStack/TensorArrayGatherV3:0", shape=(?, ?, 7), dtype=float64)It appears that the computation time does not increase with extra_samples, however, I have noticed that the sampling does take longer over time with extra_samples for very large models, though not as steeply as with mcmc. However, with large models like I normally work with, this slow linear increase can make a really big difference, to the point where the sampling slows to a near stop over time. I can’t seem to reproduce that behaviour with this example, though, so maybe I will try posting another example later.
Despite all this weirdness, greta does a fine job of coverging in this model and mixes well:
library(bayesplot)## Warning: package 'bayesplot' was built under R version 3.5.1## This is bayesplot version 1.6.0## - Online documentation and vignettes at mc-stan.org/bayesplot## - bayesplot theme set to bayesplot::theme_default()## * Does _not_ affect other ggplot2 plots## * See ?bayesplot_theme_set for details on theme settingmcmc_trace(test_mod, c("alpha", "beta[1,1]"))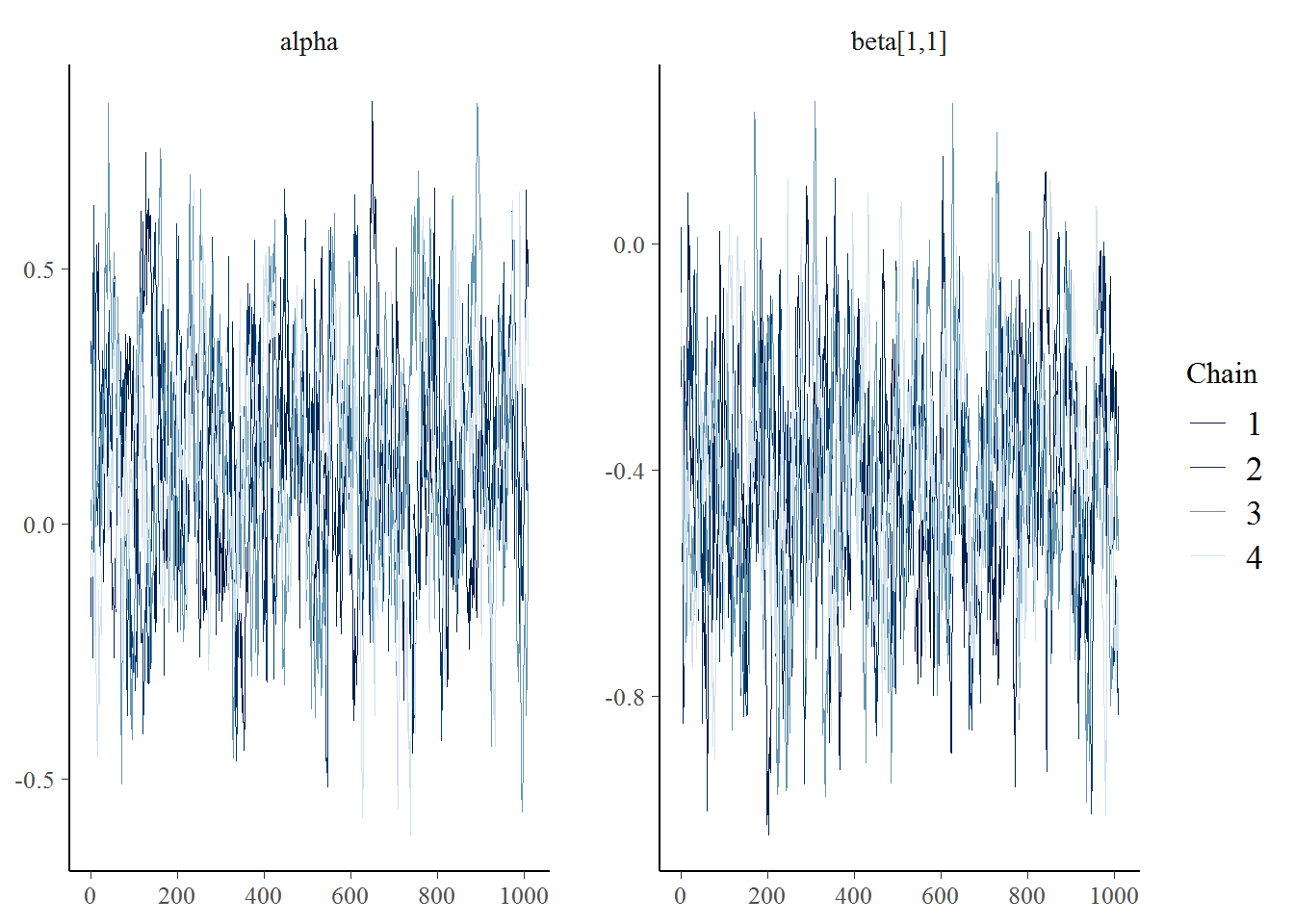
It turns out I can get the graph size back to normal by “resetting” the tensorflow session:
attr(test_mod, "model_info")$model$dag$new_tf_environment()
attr(test_mod, "model_info")$model$dag$define_tf()
test_mod <- mcmc(mod, warmup = 1000, n_samples = 10, thin = 1)##
## running 4 chains simultaneously on up to 12 cores##
warmup 0/1000 | eta: ?s
warmup == 50/1000 | eta: 15s
warmup ==== 100/1000 | eta: 10s
warmup ====== 150/1000 | eta: 8s
warmup ======== 200/1000 | eta: 7s
warmup ========== 250/1000 | eta: 6s
warmup =========== 300/1000 | eta: 6s
warmup ============= 350/1000 | eta: 5s
warmup =============== 400/1000 | eta: 5s
warmup ================= 450/1000 | eta: 4s
warmup =================== 500/1000 | eta: 4s
warmup ===================== 550/1000 | eta: 3s
warmup ======================= 600/1000 | eta: 3s
warmup ========================= 650/1000 | eta: 3s
warmup =========================== 700/1000 | eta: 2s
warmup ============================ 750/1000 | eta: 2s
warmup ============================== 800/1000 | eta: 1s
warmup ================================ 850/1000 | eta: 1s
warmup ================================== 900/1000 | eta: 1s
warmup ==================================== 950/1000 | eta: 0s
warmup ====================================== 1000/1000 | eta: 0s
##
sampling 0/10 | eta: ?s## confirm graph size is back to original
reticulate::py_len(attr(test_mod, "model_info")$model$dag$tf_graph$as_graph_def()$node)## [1] 1482attr(test_mod, "model_info")$samplers[[1]]$model$dag$tf_environment$sampler_batch[[1]]## Tensor("mcmc_sample_chain/scan/TensorArrayStack/TensorArrayGatherV3:0", shape=(?, ?, 7), dtype=float64)But obviously resetting the model like this will mess up sampling using extra_samples because it clears all of the information needed to continue the chain (not to mention losing the tuning that has occurred previously).
So, anyway, does anyone here have an idea what is going on here? Am I correct to think this behaviour is not what is expected? As I mentioned before the slowdown makes a huge difference in large models to the point where greta is unusable for me at this point. Hopefully I’m just missing something simple…
Thanks in advance for any help you can give!